An SLA Management Guide for IT Leaders
SLA management for IT leaders: vendor benchmarks by type, red-flag contract clauses, independent monitoring methods, and a step-by-step breach response playbook.

Most IT teams sign a service level agreement, file it in a shared drive, and open it again only when something breaks. By that point, the vendor has already missed three commitments, you have no documented evidence, and the contract clause you thought protected you has a carve-out that makes it unenforceable.
That is what reactive SLA management looks like. And according to ITIC's 2024 Hourly Cost of Downtime Report, the cost of a single hour of downtime now exceeds $300,000 for over 90% of mid-size and large enterprises. The financial exposure from a poorly managed vendor SLA is not theoretical.

This guide covers what SLA management actually requires in practice: the benchmarks that define a credible SLA by vendor type, the contract clauses designed to limit your recourse, how to monitor SLA performance without relying on the vendor's own data, and exactly what to do the day a vendor misses.
What SLA Management Actually Means
SLA management is the ongoing process of defining, monitoring, enforcing, and reviewing the service commitments your vendors have made in writing. It is not a contract review exercise. It is an operational discipline that runs continuously across the vendor lifecycle.
It is worth separating SLA management from service level management, which is the broader ITIL process covering how your IT team delivers services internally to the business. Service level management sets internal targets. SLA management holds external vendors to theirs. The two intersect, but they require different enforcement approaches, different ownership, and different tools.
The reason most IT teams manage SLAs reactively is straightforward: no one owns it formally until something fails. The contract team negotiated it. Procurement filed it. Operations inherited it. When a vendor underperforms, nobody has the documentation, the breach history, or the contractual standing to act decisively.
The Four Types of SLAs IT Leaders Deal With
Understanding the structure of an SLA determines how you monitor and enforce it.
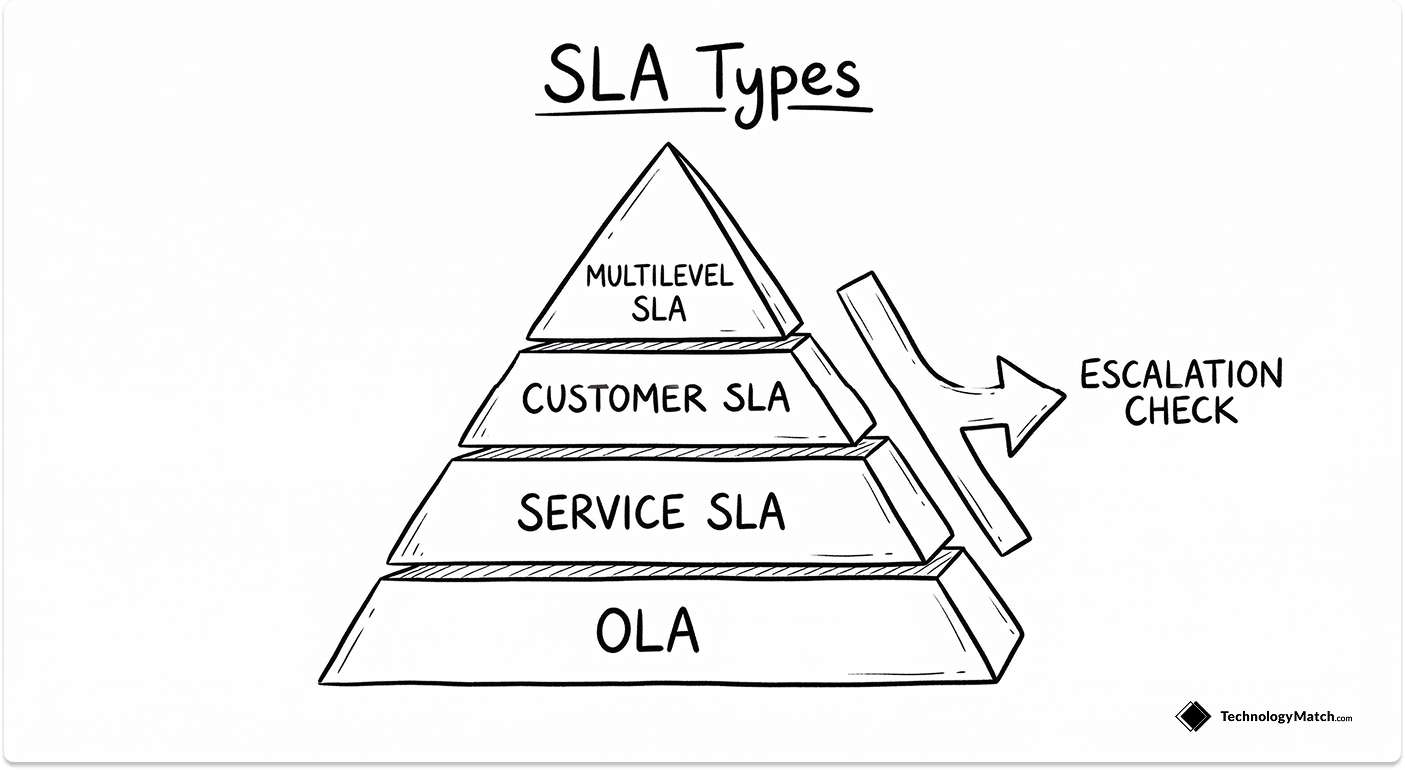
- Customer-based SLA: A single agreement covering all services delivered to one customer. Common in MSP relationships where the vendor manages multiple functions under one contract.
- Service-based SLA: One agreement for one specific service delivered to all customers. Typical for SaaS platforms that publish standard uptime commitments publicly.
- Multilevel SLA: A tiered structure with enterprise-level terms, customer-level terms, and service-level terms stacked on top of each other. Large outsourcing arrangements often use this model.
- Operational Level Agreement (OLA): An OLA sits inside your own organisation rather than with a vendor, but it is directly relevant to SLA management because an OLA failure often creates the conditions for a vendor SLA dispute.
The practical issue with multilevel SLAs is that when a breach occurs, vendors will attempt to locate responsibility at whatever tier gives them the most protection. Know which layer the breached metric sits in before you escalate.
SLA Benchmarks by Vendor Type
What a credible SLA actually looks like depends entirely on the vendor category. "Response within a reasonable timeframe" is not a metric. Here are the benchmarks that define a defensible SLA by vendor type.
MSP SLAs
Managed service providers carry broad operational responsibility, which means their SLAs need to cover the full range of incident priorities.
- P1 (critical outage, production down): Response within 15 minutes, resolution target within 4 hours
- P2 (major degradation, significant business impact): Response within 30 minutes, resolution target within 8 hours
- P3 (moderate impact, workaround available): Response within 2 hours, resolution target within 24 hours
- P4 (low impact, informational): Response within 8 hours, resolution target within 72 hours
- Uptime commitment: 99.9% minimum, equating to 8.7 hours of allowable downtime per year
- Onsite response (where applicable): 4-hour SLA for critical hardware issues
If your MSP contract does not segment by priority tier, renegotiating that structure is the first conversation to have. For a broader view of how MSP relationships should be structured from the start, the IT Buyer's Guide to Managed IT Services covers what to look for before you sign.
SaaS Vendor SLAs
SaaS vendors publish standard SLAs, which means you are often negotiating against a template designed to minimise their liability exposure.
- Uptime: 99.9% for business-critical platforms, 99.95%–99.99% for mission-critical systems (payments, authentication, core infrastructure)
- Incident acknowledgement: P1 within 1 hour from when the incident is first reported, not from when the vendor internally detects it
- Maintenance windows: Must be pre-scheduled, pre-notified (minimum 72 hours), and excluded from uptime calculations only when the notification requirement is met
- Data portability: Response time for a full data export request. Most SaaS SLAs omit this. Negotiate a 72-hour SLA for data exports before you sign.
Cloud Infrastructure SLAs
AWS, Azure, and GCP publish detailed SLAs, but most IT leaders misread how they apply.
- Compute: 99.99% uptime per region (AWS EC2), with monthly uptime measured per individual instance
- Managed databases: 99.95%–99.99% depending on deployment configuration
- Storage: 99.9%–99.99% depending on redundancy tier
The critical point: cloud provider SLAs are per-service and per-region, not platform-wide. A multi-service outage affecting compute and database simultaneously gives you two separate, limited service credits, not a compounded remedy. Architect your SLA expectations around the individual service commitments, not an assumed platform guarantee.
Hardware and On-Premises Vendor SLAs
Hardware SLAs are often the least scrutinised and the most impactful when they fail.
- NBD (Next Business Day) replacement: Acceptable for non-critical components; completely unacceptable for storage arrays or network switches in production environments
- 4-hour parts replacement: The minimum standard for tier-1 production hardware
- Mean Time to Repair (MTTR): Target below 4 hours for critical infrastructure, below 8 hours for non-critical
- Field engineer vs. remote support: Define which applies contractually. "Support" in a hardware SLA often means a phone call, not a technician on site.
A Note on Vulnerability Management SLAs
Security vendors, including EDR platforms, SIEM providers, and vulnerability management tools, require SLAs tied to CVSS severity scores rather than generic priority tiers. If you are currently evaluating vendors in this category, the Best SIEM Vendors for IT Leaders guide covers how leading platforms handle incident response and reporting. A vulnerability management SLA should specify remediation response timelines by severity: CVSS 9.0+ within 24 hours of detection, CVSS 7.0–8.9 within 72 hours, CVSS below 7.0 within 30 days. Generic P1/P2 tiers do not map accurately to security severity and create gaps that both parties will interpret in their own favour.
The SLA Clauses That Protect Vendors, Not You
Standard vendor SLA templates are written by vendor legal teams. Every clause is calibrated to minimise payout exposure. These are the ones to identify and challenge before you sign. For the broader due diligence process that should precede any contract, the IT Vendor Due Diligence guide covers what to verify before SLA negotiations begin.
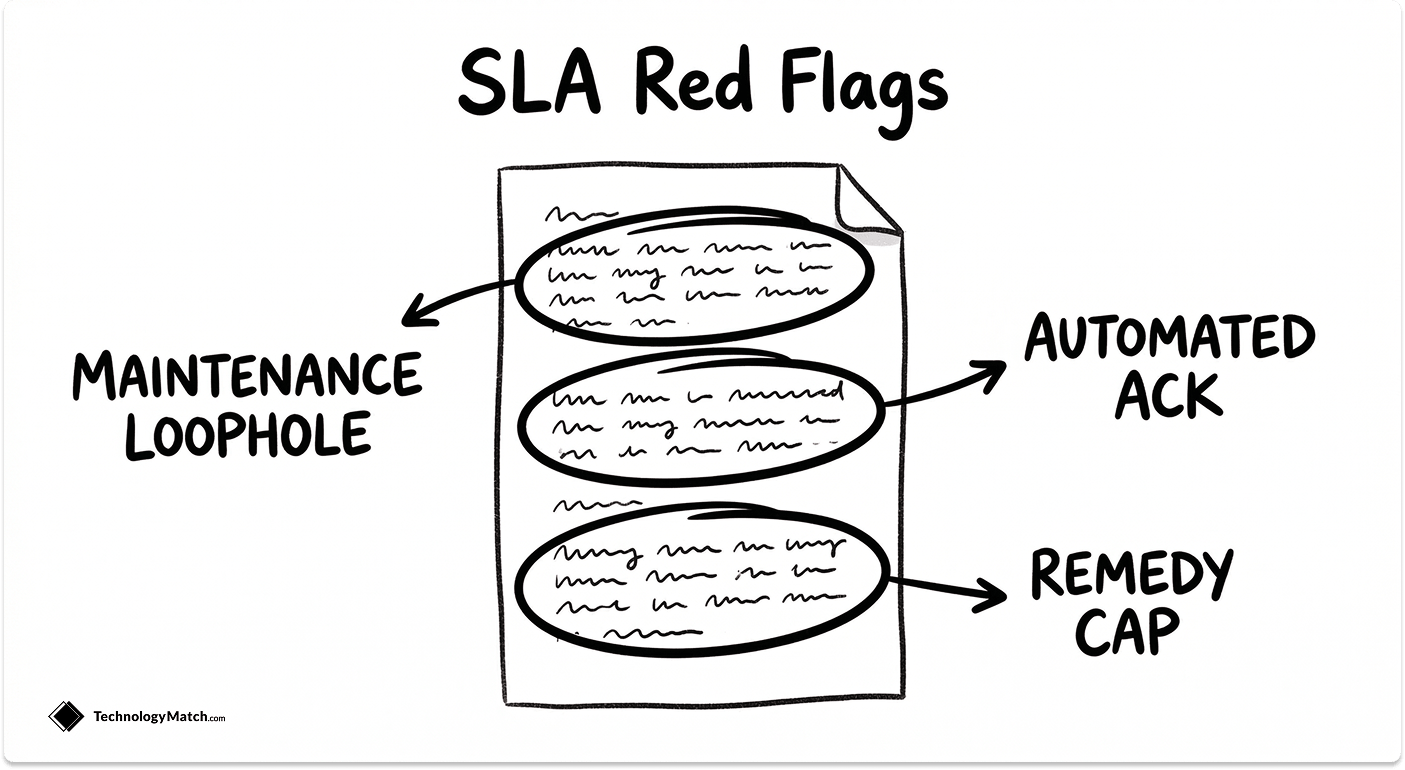
The scheduled maintenance carve-out. Vendors exclude planned downtime from uptime calculations by default. If a vendor schedules 6 hours of maintenance per month, their 99.9% uptime commitment is being measured against the remaining hours. Push for a cap on maintenance windows (4 hours per month maximum) with a minimum 72-hour advance notification requirement tied to the exclusion.
The automated acknowledgement loophole. Response time is typically measured from the moment a support ticket is opened. Vendors satisfy a 15-minute response SLA by sending an automated confirmation email. Specify engineer acknowledgement explicitly in the contract, meaning a qualified human has reviewed the issue and confirmed the scope.
The force majeure overreach. Some vendor SLAs classify cloud provider outages as force majeure events. If your SaaS vendor runs on AWS and AWS goes down, that is their infrastructure decision and their architecture risk. Push back on any force majeure clause that covers a vendor's chosen upstream dependencies.
The service credit cap. Most SLA breach remedies are capped at one month's fees, and often only on the at-risk portion of that invoice, typically 10–20% of the monthly total. On a $50,000/month contract, a major outage could cost you $5,000–$10,000 in documented damages and yield a $1,000 credit. Negotiate for higher credit percentages on P1 breaches and for termination-for-cause rights on repeated breaches.
Monthly uptime measurement instead of rolling 30-day. A vendor measured on monthly uptime can be down for 7.3 hours in a single month and still technically meet a 99.9% annual commitment. Require rolling 30-day measurement periods so that concentrated outage periods are reflected accurately.
The customer-caused exclusion. Vendors can attempt to void SLA obligations by attributing downtime to customer-side configuration issues. Ensure any customer-caused exclusion requires the vendor to demonstrate causation with specific evidence. The default position should be that the vendor carries the burden of proof.
How to Monitor SLAs Without Relying on the Vendor's Own Data
Vendors report their own uptime. The conflict of interest is obvious. SLA monitoring built entirely on vendor-supplied data is just a summary of what the vendor chose to tell you.

Synthetic monitoring is the most reliable independent verification method. Tools like Datadog Synthetics, Catchpoint, and Pingdom simulate real user transactions against your vendor's platform continuously. When your synthetic tests detect degradation ahead of any vendor incident report, you have timestamped, independent evidence that sits outside the vendor's control.
Third-party uptime trackers aggregate StatusPage data and provide independent monitoring records. Services like IsDown and Better Uptime pull status data directly from vendor infrastructure and create an audit trail you own.
Log correlation gives you a second verification layer. Cross-reference your internal application logs against the vendor's reported incident windows. If your logs show failed API calls for 47 minutes but the vendor's incident report claims a 12-minute impact window, that discrepancy is your evidence in a credit negotiation.
SLA reporting cadence matters as much as the tools. Establish monthly SLA reporting reviews with every tier-1 vendor. Require the data in a format you specify: raw incident logs, uptime calculations with timestamps, and open P1/P2 tickets with current status. A dashboard the vendor controls is not a report.
SLA management software such as ServiceNow, Jira Service Management, and dedicated contract management platforms like Ironclad centralise SLA tracking across your entire vendor portfolio. At 5–10 vendors, a well-maintained spreadsheet is sufficient. Beyond that, the operational overhead of manual tracking introduces the same gaps you are trying to close. The IT Vendor Compliance Framework covers how to structure ongoing oversight across your full vendor portfolio.
The Escalation Ladder
Escalation mentioned in one sentence is not an escalation process. The ladder needs to be agreed and written into the contract before you ever need to use it. Without pre-defined thresholds, escalation is just an uncomfortable phone call with an account manager.
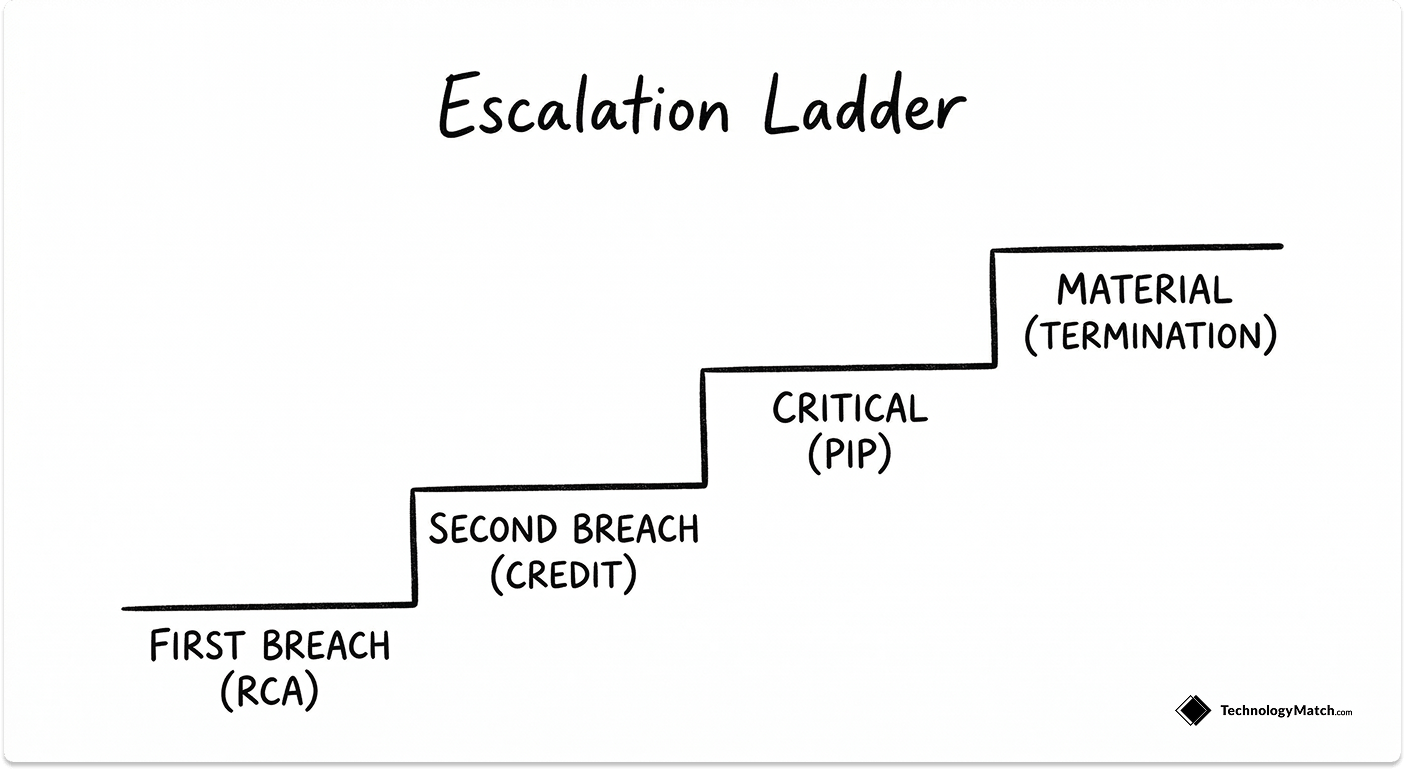
Level 1: First breach. The vendor opens a Root Cause Analysis within 48 hours. Your IT team lead receives a written explanation of what failed, why it failed, and what the vendor is changing to prevent recurrence. No financial consequence at this stage, but the breach is formally documented and logged against the vendor's breach history.
Level 2: Second breach of the same SLA metric within the same quarter. An automatic service credit is triggered at the percentage specified in the contract. Escalation moves to the vendor account manager. A written remediation plan with specific timelines is required within 5 business days. Both parties sign off on the plan.
Level 3: Third breach or any single critical SLA failure (P1 extended beyond the resolution target). Escalation reaches vendor VP or C-suite level. Enhanced service credits apply, typically at double the standard rate. A formal 30-day Performance Improvement Plan is initiated with defined success criteria and a stated consequence for failure to meet them.
Level 4: Repeated breach or material failure. Termination for cause rights activate with no financial penalty to your organisation. You retain the right to source an emergency replacement vendor and to seek clawback of any pre-paid fees covering the affected service period.
The ladder only functions if breach is defined with a specific numeric threshold in the contract. Material breach without a measurement definition is not enforceable. The IT Vendor Relationship Lifecycle guide covers how escalation processes fit into the broader vendor relationship from onboarding through to offboarding.
What to Do the Day a Vendor Breaches an SLA
This is the highest-pain moment in any vendor relationship and it is completely absent from every competing article on SLA management. Here is exactly what to do.
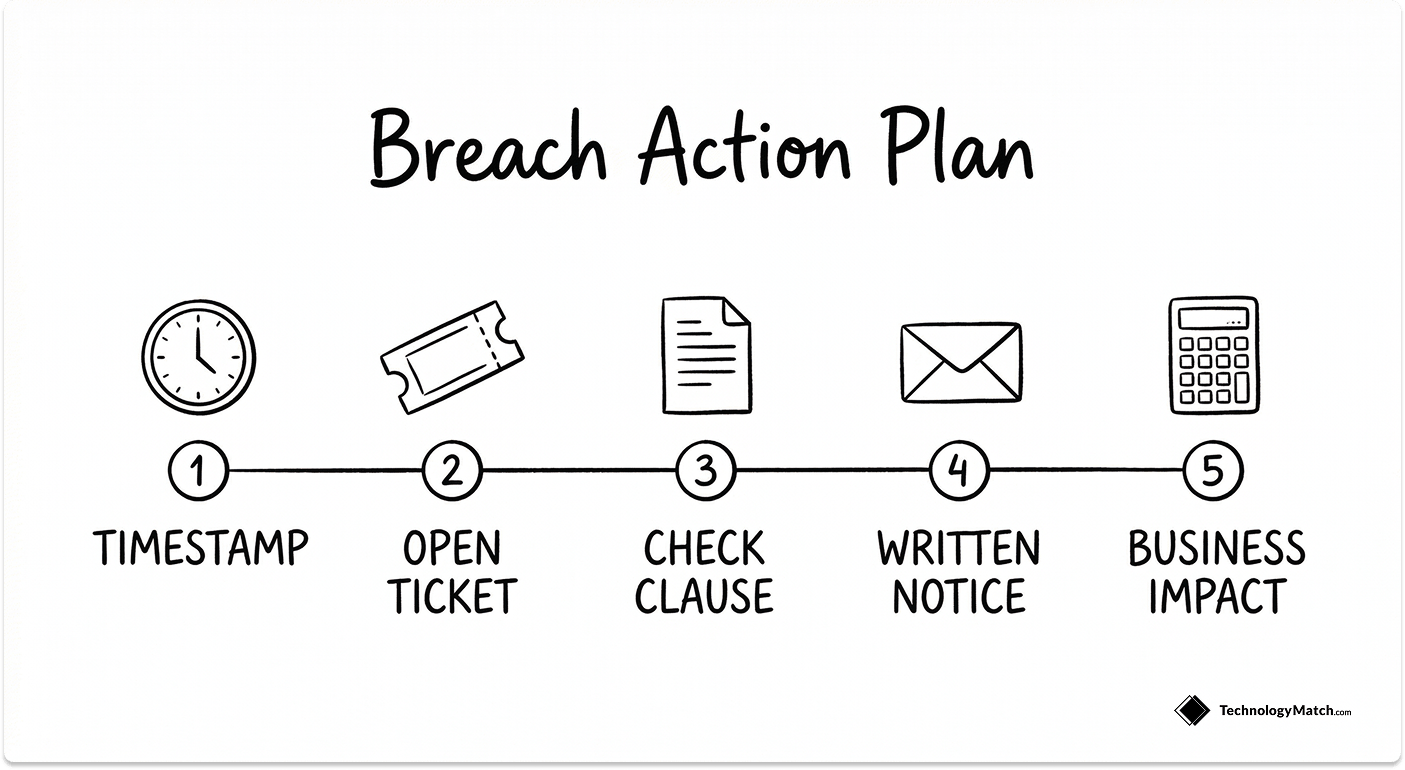
1. Timestamp everything using your own monitoring data. The breach clock starts when the incident began, not when the vendor opened a ticket. Your synthetic monitoring or independent uptime tracker gives you the independent timestamp. Do not let the vendor define the incident window.
2. Open a formal support ticket immediately. Even if you have called the account manager. Even if they are already aware. The contractual response time clock is tied to a ticket, not a conversation.
3. Pull the contract. Confirm the exact SLA metric that was breached, the measurement window it falls within, and the remedy clause that applies. Do this before your first written communication with the vendor.
4. Issue a formal breach notification in writing within 24 hours. A breach notification email creates a legal record and prevents the vendor from later claiming they were not formally informed. It also starts the clock on their RCA obligation.
5. Quantify the business impact. Document the number of users affected, the duration of the impact, and the operational cost. Use a simple formula: users affected multiplied by average hourly productivity cost multiplied by duration in hours. This figure is your basis for any compensation claim above the standard service credit.
6. Invoke Level 1 of the escalation ladder immediately. Do not wait for the vendor to resolve the issue informally and then offer a goodwill credit. Move the incident through the formal process from day one.
7. Track the Root Cause Analysis. The RCA is your evidence that this was a vendor-side failure. If the vendor's RCA attributes any portion of the failure to your environment, challenge it in writing with your independent log data before signing off.
SLA Management for AI and SaaS Vendors
AI vendor SLAs are still largely written using standard SaaS templates, which do not account for the specific failure modes of LLM infrastructure. If you are evaluating or managing AI vendors, these are the SLA terms you need to define.

API latency commitments. Most AI vendors commit to uptime but say nothing about inference speed. Push for p95 latency targets per request type. A platform that is technically up but returning responses in 30 seconds is not meeting your operational requirements.
Model availability versus API availability. A vendor can report 99.9% API uptime while the underlying model is in a degraded state. These are two different measurements. Require them to be tracked and reported separately.
Data residency and processing timelines. Define contractually where your data is processed, under which jurisdiction, and how quickly it is deleted after inference. This is increasingly a compliance requirement under GDPR and emerging AI governance frameworks.
Rate limiting as a service degradation metric. If a vendor throttles your API calls during peak load, that is a reduction in available service. Get rate limits contractually defined and included within the scope of your uptime and availability SLA.
Model version stability. LLM providers can update or deprecate model versions without notice, changing outputs in ways that break your workflows. Negotiate a minimum 90-day notice period before model deprecation and, where possible, a version lock option for production workloads.
SLA Management Best Practices
Build SLA requirements into the RFP stage, not the contract stage. By the time you reach contract negotiation, the vendor has invested time in the deal and your leverage is reduced. Requiring specific SLA terms in the RFP means vendors self-select based on what they can actually deliver, and you compare vendors on standardised commitments. The IT Vendor Management KPIs guide covers which metrics to build into those RFP requirements by vendor type.
Segment vendors by criticality before negotiating. Tier-1 vendors running mission-critical systems need bespoke SLAs built around your specific operational requirements. Tier-3 commodity vendors can work with standard templates. Applying the same negotiation rigour to every vendor is not efficient, and applying no rigour to any vendor is expensive.
Review SLAs annually at minimum. Specifically, after any significant breach, when your usage of the service materially changes, when the vendor undergoes ownership or platform changes, and at every contract renewal. An SLA written when you had 200 employees is not fit for purpose at 2,000.
Keep a centralised SLA register. For every tier-1 and tier-2 vendor, maintain a record of the vendor name, service category, key SLA metrics and thresholds, breach history by quarter, escalation contacts, and contract renewal date. A spreadsheet manages this up to roughly 20 vendors. Beyond that, the manual coordination overhead argues for dedicated SLA management software.
Never accept verbal commitments on performance. If a vendor says they will always respond in under an hour, that statement is worth nothing. Any commitment that matters needs to be in a signed addendum to the contract. Account managers change. Goodwill does not survive commercial disputes.
The SLA management market is growing for a reason. According to Persistence Market Research, the market is projected to grow from $2.4 billion in 2026 to $6.1 billion by 2033. That growth reflects the operational reality that vendor relationships are becoming more complex, more numerous, and more consequential to IT delivery. The teams that manage SLAs formally, with documented benchmarks, independent monitoring, and a pre-defined escalation process, are the ones who resolve vendor failures in days rather than quarters.
Looking for IT partners?
Find your next IT partner on a curated marketplace of vetted vendors and save weeks of research. Your info stays anonymous until you choose to talk to them so you can avoid cold outreach. Always free to you.
FAQ
What is SLA management in IT?
SLA management is the ongoing process of defining, monitoring, enforcing, and reviewing the performance commitments your vendors have agreed to in writing. It covers the full vendor lifecycle, from negotiating the right metrics before signing to documenting and escalating breaches when they occur. The distinction that matters: SLA management governs external vendor relationships, while service level management (the broader ITIL discipline) governs how your IT team delivers services internally to the business.
What are the key metrics to track in a vendor SLA?
The right metrics depend on the vendor type. For MSPs, track P1–P4 response and resolution times, uptime percentage, and onsite response commitment. For SaaS vendors, track uptime against a rolling 30-day window, P1 engineer acknowledgement time, and maintenance window frequency. For cloud providers, track per-service uptime separately — compute, storage, and database SLAs are independent commitments. For security vendors, map response SLAs to CVSS severity scores rather than generic priority tiers.
What should I do when a vendor breaches an SLA?
Timestamp the breach using your own independent monitoring data, open a formal support ticket immediately, and pull the contract to confirm the exact metric and remedy clause before communicating with the vendor. Issue a written breach notification within 24 hours, quantify the business impact in documented form, and invoke the first level of your pre-agreed escalation ladder. Do not accept an informal resolution or goodwill credit in place of the formal process — it sets a precedent that the contract terms are optional.
How do I monitor SLA compliance without relying on vendor reports?
Use synthetic monitoring tools such as Datadog Synthetics, Catchpoint, or Pingdom to simulate real transactions against your vendor's platform continuously. Cross-reference your own internal application logs against vendor-reported incident windows to identify discrepancies in impact duration. Third-party uptime trackers like IsDown and Better Uptime create an independent audit trail. For formal SLA reporting, require vendors to provide raw incident logs and uptime calculations in a format you specify, not a dashboard they control.
What SLA terms should I negotiate before signing a vendor contract?
Five areas to address before signing: cap scheduled maintenance windows at 4 hours per month with a 72-hour advance notification requirement. Require engineer acknowledgement as the response time trigger, not automated ticket confirmation. Push back on any force majeure clause that covers the vendor's own upstream cloud dependencies. Negotiate service credit percentages above the standard 10–20% of monthly fees for P1 breaches, and include termination-for-cause rights on repeated failures. Require rolling 30-day uptime measurement rather than monthly, so concentrated outage periods are accurately reflected in your SLA calculations.